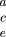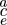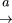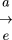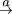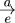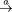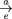<ART>
Description: Article
art is the top-level element for every article in the HighWire DTD. At the highest level, an article can be split into the following parts: copyright information, document head, document topic(s), document subject(s), front matter, body matter, back matter, and response(s). Only the copyright element is mandatory.
The art element has a number of attributes that specify basic information about the article. These are: version (version number), jid (journal identifier), aid (article identifier), vol (volume number), issue (issue number), fpage (first-page number), and lpage (last-page number), all of which are required and should be self-explanatory.
version is a fixed attribute denoting the version of the DTD that is to be used with the article in question.
doi is an optional attribute to contain the DOI (digital object identifier) for the article, if one is available.
pmid is an optional attribute to contain a PubMed ID for the article, if one is already known.
sici is an optional attribute to contain the SICI (serial item and contribution identifier) for the article, if one is available.
The journal identifier jid must contain the lowercase HighWire code for the journal in question, exactly as it has been given to you. The article identifier aid, while not normally used by the parser, should match the name of the SGML file (without the file extension). The fpage attribute may contain a "subpage" letter, e.g. 10-a, in the case of multiple articles beginning on the same page.
The language attribute can be used to specify the main language of the piece. If none is specified, the default is en (english). Other options are de (german), es (spanish), fr (french), it (italian), pt (portuguese), or ru (russian).
Example of an <art> line:
| <art version="4.2.12HW" jid="sjrnl" aid="1241197" vol="124" issue="6" fpage="1197" lpage="1207"> |
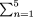 n
n
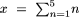
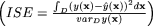

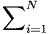
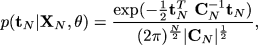 (1.1)
(1.1)